
Regressing the Log Function with Neural Networks
What if you were given and asked to guess and , would you be able to provide a satisfying pair of ? Sure you can; one could do and then choose and to their liking. But the issue is that, if and are predefined and we only get , then there is no mathematical rule to get back and . The only way would be brute forcing (trying all pairs of and until we get the correct one) and an oracle then tells us whether our chosen and is correct. But can neural networks figure this out if we supervise them?
In this series of experiments, we tested to see if fully connected neural networks (FCNs) can undo a logarithm and an addition to predict and from . Hence, the input is a single number i.e. and the outputs are and . The FCNs had one or two hidden layers, each with a number of nodes of 10, 50, 100, 500 or 1000 and even 50,000. Most experiments were done for 500 epochs, but a few for 1000 epochs, which will be mentioned below. The Adam optimizer was used and a learning rate of 0.001 worked best.
For evaluation, the score and the output residuals were observed, since this is a regression task. The score can range from large negative numbers (badly fitted models) to a maximum perfect score of 1. So, models with scores close to 1 are skilled models. The output residual is simply the absolute difference between the prediction and the label, so lower is better.
The dataset was generated, where numbers between 0 and a maximum were generated uniformly and randomly, then the input was calculated and the were used as labels. Then these values were normalized by their respective maxima. The dataset consisted of 10,000 of these input- output sets and the maximum or were between 100 and 1000.
The results reveal that these FCNs are not good at reversing the logarithm and addition, with the best model having a score of 0.55.
For FCNs with one hidden layer, having more nodes leads to better scores, but not by a big margin. Hence, having 50,000 nodes (red line) gave the maximum score of 0.55, but in spite of training for 1000 epochs, the score plateaued very early.
For FCNs with two hidden layers, increasing network size doesn’t improve score. In fact, the nodes network had the maximum score (red line), while even bigger network sizes of, say, performed a little worse. But even here, the score levels off early at 0.55.
The output residuals had an amazing distribution: a bell shaped curve, which is a pretty neat Gaussian. This means the predicted and are off by a certain amount in most cases.
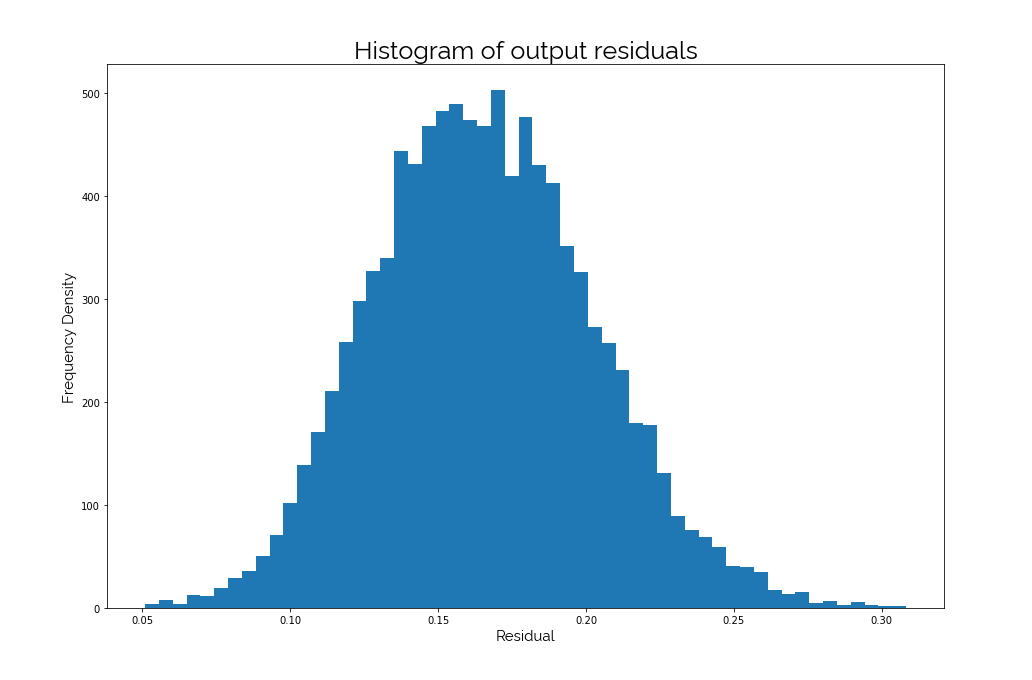
These experiments conclude that FCNs will not be effective when mapping relationships that involve reserving a logarithm and addition.
This experiment was inspired by Multiplying large numbers with Neural Networks and uses the code from there as well.
The code and experimental data for these results can be found in this repo.




